Mac OS X’s Preview: When a space is not a space
Posted by Pierre Igot in: MacintoshJuly 13th, 2007 • 12:29 pm
This is a strange one.
I have this PDF file that I have to translate. I typically use Mac OS X’s Preview for viewing PDF files, simply because it is much more compact and efficient than Adobe’s bloated applications. But it has its flaws, obviously. But this is a really strange problem.
Since I am translating the document, I frequently have to select phrases in the text and copy and paste them in other applications (usually a terminology database form or the Google search field in Safari). Most of the time, this task involves strings of text consisting of whole words. So I typically use a double-click on the PDF file to select the first word in the phrase that I want, and then drag my mouse to extend the selection word by word until I have everything.
The strange thing is that, in this particular document, whenever the word that I double-click on has a punctuation mark attached to it, be it a comma or a semicolon, Preview automatically selects not only the word that I am double-clicking on, but also the next word, even though there clearly is a space after the punctuation mark.
Here is an example. In the picture below, I have just double-clicked on “council.” This should only have selected the word “council” itself, and then maybe the comma that comes after it. (Unfortunately, text selection tools are not always smart enough to exclude punctuation marks from the selection.)
Yet here is what happened:

This is quite strange, in that there clearly is a space after the comma. I tried to reproduce this elsewhere in the same PDF file, and indeed, in Preview, whenever I double-click on a word followed by a comma or a semi-colon, the application automatically selects the next word at the same time. Worse still: if I double-click on the first word in a series of words separated by commas, Preview selects the entire series at once!
To confirm that there is a problem in Preview with this file, I tried copying the selected phrase and pasting it in a word processor or text editor. When I do this, Mac OS X actually inserts “council,school,” i.e. without a space after the comma between “council” and “school.”
In other words, there clearly is something in this particular file that causes Preview to think that there is no space here. Of course, if it thinks that there is no space, it is logical that it also thinks that it is a single word. And so a single double-click on it selects the whole thing.
Fortunately, Preview does not have the same problem with other PDF files—only this particular one.
Out of curiosity, I opened the same PDF file in Acrobat Professional, and tried to reproduce the same problem, to no avail. When I double-click on “council” in the same PDF in Acrobat Pro, Acrobat correctly selects the “council” word only:

So Acrobat clearly recognizes the spaces after commas and semi-colons in this PDF file as normal spaces. But for some reason Preview doesn’t.
At this point, I started wondering whether the PDF file was created with some Windows authoring program that would have used non-standard space characters that Mac OS X’s Preview might not recognized. So I looked at the document information in Acrobat for this particular file, and here’s what I saw:
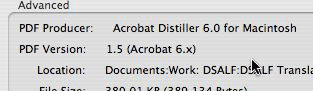
In other words, the PDF file in question was actually authored on a Mac, with Acrobat Distiller 6!
This makes the behaviour in Preview all the more puzzling. Surely PDF files generated by the Mac version of Acrobat Distiller should behave properly when opened in Mac OS X’s Preview… Yet this one clearly does not.
I am afraid there is not much point in investigating this any further. There is just no way that I can get a hold of the graphic designer who actually authored this document. There are too many intermediates. I guess I’ll just have to use an Adobe application for this particular PDF file.
But this particular incident shows that, unfortunately, the basic premise of the PDF file format, which is to provide a document format that can be read and used by everyone on all platforms with free reader applications, has yet to be fully realized. And Preview, as a PDF reader application, does have a number of annoying and unexplained issues with certain PDF files that Adobe’s applications don’t seem to have.
July 13th, 2007 at Jul 13, 07 | 1:43 pm
It might be interesting to see what is stored in the PDF file itself. Perhaps there is no space in the text but just the position of the first glyph of the new word is given. And possibly Acrobat Reader is smarter as recognising such situations as spaces than Preview is.
Just as Preview generally fails when it comes to multi-line selections on multi-column pages or at copying hyphenated words.
As much as I like Preview (and I only refuted to using Acrobat about twice since X.3 was released, as I mostly use it for simple tasks), it’s just not particularly good at these things.
July 13th, 2007 at Jul 13, 07 | 3:45 pm
I tried to open the PDF file with BBEdit, but all I see is a few bits of data at the beginning and then garbage, so that doesn’t tell me much. I am not sure what you mean by “stored in the PDF file itself.”
If you have any other tools for this, here is a link to a sample page from the file in question.
I agree that Preview is not particularly good at text selection in PDF files, but much of it depends on how the PDF was created in the first place. And sometimes Adobe Reader is not much better—and I get better results with Acrobat Pro or with the free PDF2RTF service.
July 13th, 2007 at Jul 13, 07 | 5:20 pm
That sample page viewed in Word there appears to be a invisible character that looks like the paragraph symbol but with the top chopped off. Perhaps some odd control character was used in making that PDF?
July 13th, 2007 at Jul 13, 07 | 8:46 pm
Preview has all kinds of strange behaviors related to text selection and copying. For instance, most of the time you cannot use Preview to correctly copy text from OCR-ed documents created by Acrobat Professional. Spaces get inserted between letters for some strange reason. It works properly, of course, in Acrobat Reader.
July 14th, 2007 at Jul 14, 07 | 6:20 am
“But this particular incident shows that, unfortunately, the basic premise of the PDF file format, which is to provide a document format that can be read and used by everyone on all platforms with free reader applications, has yet to be fully realized.”
Thats a bit of a reach to suggest this due to a small error in Preview.
July 14th, 2007 at Jul 14, 07 | 11:20 am
artMonster: I am not sure how you opened a PDF file with Word. Word 2004 certainly is not capable of doing this. Besides, even if it were able to open it, I am not sure I would trust what it says about what the characters are. :-)
Alan: Agreed—although I do not use OCR myself. I have noticed a number of text selection problems. But Adobe Reader has some problems too, depending on the file. I think a lot depends on how the PDF file was created, and with which tool.
Project: This particular incident is just an example of more widespread problems. I could list a number of issues with text selection, or with character encoding, which affects more than just one single PDF file.
July 14th, 2007 at Jul 14, 07 | 2:42 pm
The opportunity to copy text from the screen display of a PDF file is not part of the intended function, so I’m not surprised that it works inconsistently. I have had my own, different problems with copying text from Acrobat Reader displays.
Adobe’s goal is to provide a document format that everyone can view –with a reader program– but almost certainly producing characters that are select-able and copy-able is something Adobe would have rather avoided in their own reader output and have no/less control over in someone else’s. (Does Apple license the reader technology and use Adobe’s code in Preview?)
Presumably, Adobe’s money-maker in this technology is licensing full Acrobat to large companies, which seek _some_ control over the content of their documents. Companies cannot prevent all copying, and I don’t think they want to. They can generally impede people from making full-resolution electronic copies of entire documents, and it seems that the PDF technology does this pretty well.
But you can’t expect perfect text-copy from PDF readers because that’s functionality counter to the purpose of the technology, the reason Adobe’s big customers pay for producing PDFs.
How often have you downloaded a PDF from a corporate website, viewed the document, tried to print to a physical printer, and been prevented by password protection? I suspect that Adobe’s big customers would have liked to see text-copying under similarly tight control and Adobe would have provided it, but this just wasn’t practical.
July 14th, 2007 at Jul 14, 07 | 3:04 pm
Henry: Text copying from PDF files can also be protected by password. The core issue here is that PDF is not just a corporate-friendly file format for distributing documents with various restrictions, but also a user-friendly file format for sharing resolution-independent, printer-ready documents between users of various platforms with various font collections, etc.
There is no doubt, however, that the user-friendly aspect of PDF is probably not the prime motivator for Adobe. But the reality is that PDF is used by ordinary people to share documents and that it is not these people’s intention to prevent the recipient from being able to copy the text. The main purpose of using PDF is to provide a document that is readable on any platform and is printer-ready, with tight control over page layout and text formatting. The lack of support for copying text is mostly a side-effect and not something intentional on the part of the author of the PDF. That is why I think software developers such as Apple and Adobe could put more effort into making it easier to copy text when the author is perfectly willing to allow it. But of course the only incentive for Apple and Adobe to do so would be user-friendliness, and we all know how much that matters in the computer industry these days.
In this particular case, I think it is quite obvious that the author of the PDF file in question did not intend to prevent me from copying his text, and certainly did not intend to replace regular space characters after commas and semi-colons with something weird that causes Preview to misbehave.
July 14th, 2007 at Jul 14, 07 | 3:10 pm
Virtually all the PDFs that I’ve seen cause problems in Preview are generated by Acrobat Distiller prior to v7, rather than other tools; and those invariably work in Acrobat. On the other hand, I frequently manage to generate PDF files with Adobe InDesign that don’t render properly in Adobe Acrobat, but do render properly in Preview.
Oh, now that’s a bit iffy. This vision of PDF is one that has been retrofitted onto the format by the wider community of computer users, after it had already become a de facto standard. The basic premise of PDF is more like “leverage PostScript for document interchange in a way that makes Adobe money.” (Remember the $50 Acrobat Reader 1.0?)
PostScript is very good at making sure you get the same visual on different devices; but it’s a visual format; it really doesn’t get into the semantics of its text. Since Acrobat Distiller is starting with printer-bound PostScript data, it generates a PDF that you know will print correctly, but whose text may be represented in very weird ways.
July 14th, 2007 at Jul 14, 07 | 3:26 pm
OK, instead of “the basic premise,” I probably should have said, “the fundamental usefulness.” I agree that PDF probably didn’t become what it has become by design… After all, it’s not like Adobe could have anticipated Apple using PDF as one of the building blocks of Mac OS X’s printing architecture, for example. But the fact of the matter is that it is what PDF is used for by many people today.
July 14th, 2007 at Jul 14, 07 | 4:46 pm
The reason I nitpick is just to point out that the mismatch between what the format was built for and what it’s used for can go a long way toward explaining why it sometimes doesn’t seem to work. In a case like this, the format and all the involved software are actually doing their job — displaying the same data across platforms in a printable manner. As far as both the source data (the PostScript that went into Distiller) and the priorities of the PDF file format are concerned, text selection is essentially not a concern.
Of course, the behavior still annoying and frustrating, and there are certainly ways that Preview can and should improve on this.
(In the long term, though, the solution will come from applications generating smarter PDFs instead of just shoving printer output through something like Distiller.)
July 14th, 2007 at Jul 14, 07 | 5:46 pm
@henryn: Of course I can expect PDF to provide conveniently accessible files which I can copy from without problems. Why shouldn’t I? And I have had plenty of files in which things like text selection work just fine when done in Acrobat Reader (even files where an old document had been scanned and you see the original scan but you can still select the text and copy it because some OCRed version of the text seems to be attached to it). So the PDF format as it exists today definitely seems to be up for all this.
Yet Apple’s implementation of it leaves a lot to be desired when it comes to these more advanced features. Or even to somewhat basic features such as letting the user select text. And that’s a shame. Apple got a good start with PDF both in their display speed and with things like indexing. But they are starting to be less and less impressive as they are not keeping up as PDF and its uses evolve.
@Pierre: I don’t know enough about the internals of PDF but I’m pretty sure the text must be stored in the file ;) What could give you a hint is opening the PDF in Illustrator and looking at the different layers there. This pretty much reflects what I tried to say initially. The characters/words are placed in the file individually. I presume that the scheme is that a new block of text is started at a certain position and keeps running until there is some positioning (like spacing or kerning) that doesn’t come straight from the font’s metrics. In which case a new block is started. While I don’t know the PDF internals, that’d seem like a pretty reasonable approach to me and you could consider it to be confirmed by your file.
July 14th, 2007 at Jul 14, 07 | 10:32 pm
ssp: I think that’s a pretty good summary of how the text appears to be handled, with the exception that sometimes even things that are part of the font metric can cause new blocks of text. For instance, fonts that have numbers that descend below the baseline can create PDFs that appear to have new blocks of text with each number (if they’re created through Distiller or other print-to-PDF tools).
PDFs created by a program that’s really PDF aware can include more information about how the text blocks flow, and can do all sorts of nifty things like the PDF+Text format that does the OCR tricks. PDF is a tweaked superset of PostScript, and those tweaks can do some really cool things.
But a PDF from Distiller is inherently one that cannot use those superset features, because it was created from PostScript.
July 15th, 2007 at Jul 15, 07 | 10:42 am
ssp: The problem is that the text is not visible in a text editor. When opening the PDF with Illustrator, it quickly becomes apparent that this is one of those files where the text has actually been chopped up into a myriad of smaller chunks (one letter or a few letters at a time). Sometimes the chunks are whole words, but most of the time they are just smaller strings, with no logic whatsoever. So it’s effectively impossible to select phrases in Illustrator. And the spaces between words don’t appear as space characters, but as emptiness between the chunks.
This is not unusual in PDF files (I have opened PDF files in Illustrator before) and is obviously something that happens when the PDF is generated. I guess both Adobe Reader and Preview actually have to somehow reverse the chopping up in order to make the text selectable. They obviously each use their own algorithm for this, and Adobe’s algorithm must be somewhat better.
So in effect it all boils down to Preview not being very good at making text selectable in some PDF file.
July 15th, 2007 at Jul 15, 07 | 12:05 pm
Definitely Pierre. In case you aren’t aware of that, Preview is not just ‘not very good’ but rather extremely bad. I think it’s safe to describe Preview’s selection algorithm as simply taking characters from left to right and top to bottom on the page regardless of the distances between them.
E.g. if you have a document that has a normal text in it and a vertical note at the outer side of its margin, Preview will include characters of the margin text if you do a multi-line selection of the main text…
July 16th, 2007 at Jul 16, 07 | 2:01 pm
Well, when I really need text selection flexibility, I usually convert the PDF to RTF using one of the tools mentioned above. I only really need to be able to select short phrases here and there. But of course Preview could be much better at figuring out what constitutes paragraphs, etc.
That said, Safari is not without its own problems when it comes to text selection…
July 16th, 2007 at Jul 16, 07 | 8:27 pm
Almost certainly the PDF in question does not contain the space where you are expecting it.
At the page level, PDF’s contain a stream to be rendered when displayed. For text this often consists of a series of text runs. These essentially are like, “set up the drawing transform like x, y, z, draw glyphs ‘abc'”.
Text Runs often are only three or four characters.
There is no requirement whatsoever that there be actual space glyphs in the PDF. What looks like a physical space can simply be that the two words were drawn a bit apart from one another.
Files whose life began as PostScript almost never have space characters. The PDF-ripping software I am aware of are not going to remedy this either (that is, they are not going to be able to insert these space characters during the rip).
Even the better behaved PDF’s that have spaces between words almost never have the spaces at the end of lines of text. Or linefeeds or carriage returns. So PDF Kit (Preview uses PDF Kit) has a difficult job.
In some cases it sees there are no spaces on a given page and tries to use some fuzzy logic to determine where to insert spaces (looking for large gaps between characters). This is very document dependent. We’re lucky to get 90% success with this.
Worse perhaps are the semi-well-behaved documents that have some, but not all spaces. We are not very aggressive at inserting spaces at all for these documents.
To be sure, Adobe does a better job handling these areas. No doubt Apple will concentrate more in the future on better algorithms for detecting spaces in PDF”s without them.
Paragraphs and columns (like spaces) are illusion as well. The recent PDF spec allows for formatting information for a page, but guess how many PDF’s in the “real world” you run into that have this additional formatting? Regardless of course, you have to handle the older cases in any event….
If you have any tools that can de-FLATE the said PDF you can probably observe the missing spaces yourself (it must be FLATE encoded if it looks like garbage in BBEdit).
Sadly PDF was never advertised as being a word-processing-style format. PostScript-converted to PDF, OCR, missing glyph-to-UNICODE mapping tables, “double-struck” (overlapping) text runs are all problems when trying to treat PDF as another text file format you can select and copy from.
July 16th, 2007 at Jul 16, 07 | 11:07 pm
Thanks for the insights, John. What I do find interesting is that, when I use Mac OS X’s built-in PDF architecture to create a PDF file from, say, a Pages document, and then open it in Illustrator, most paragraphs of texts consist of chunks of text that are usually whole lines. (There are a few exceptions here and there.) Yet in other PDF files, like this document produced by Distiller, the text is divided into much smaller chunks.
And if I take the same text and place it in an InDesign publication, and then export it as PDF, again I get much bigger chunks.
And again if I create a PDF from my Pages document with Distiller (CS3).
So it looks to me like the issue also has lots to do with the algorithms that are used to create the PDF files in the first place—and possibly also with various font settings. (For example, in the problem PDF mentioned above, there are lines where the space between chars—the tracking—is bigger, and these lines end up as individual characters in the PDF as exposed in Illustrator, whereas for the other lines in the same page, the chunks are bigger.)
Anyway, the basic issue here remains that Pages fails to “see” certain spaces (after commas and semi-colons) in this particular document, whereas Acrobat does. I don’t see why Preview can “see” the other spaces in the lines of text, but not the spaces after the commas and semi-colons. It looks like a bug to me, rather than just a slightly less effective algorithm.
July 17th, 2007 at Jul 17, 07 | 6:27 pm
I found the PDF file you refer to: “REFERENCE_GUIDE_FINAL_15_March.pdf”.
A quick Google search with some of the words you illustrated found it here:
http://www.dukeofed.org/ns/docs/REFERENCE_GUIDE_FINAL_15_March.pdf
So I checked it out.
In fact there are physically no space characters in the PDF after the comma character in the example you site (on page 5).
This makes the PDF in my mind of the worst kind. It has some spaces in the document but not everywhere…. This goes back to the algorithm point I was making earlier.
So, try not to beat up Preview too badly — perhaps take your ire out on the creator of the PDF (or perhaps the looseness of the PDF spec itself).
Again, I’m not denying that Adobe does a much better job with these edge cases (a richer algorithm to detect and insert spaces). To help improve Apple’s technology though, I’m to going to go ahead and file a bug against PDF Kit and attach this PDF as a reference.
Perhaps a future Preview will better measure up to Adobe in these regards.
July 17th, 2007 at Jul 17, 07 | 11:01 pm
Good job with fishing out the original document! :-) I could have shared this information with you myself… As you found out, the document is in the public domain.
I agree that this PDF is probably a “bad” PDF, but the reality is that, just like badly coded web pages and badly formatted Word documents, we have to live with them, and software applications have to deal with them as well.
As you can easily imagine, there is not much I can do in my position about the situation. This particular document was probably contracted out to a graphic designer, and either the designer himself or the PDF authoring tool he used are responsible for this. And it’s not like it’s a major issue with the document that makes it unreadable or unprintable. It’s effectively one of those many more minor issues that professional Mac users have to deal with on a daily basis in a world dominated by badly designed software used by badly trained people.
Thanks for filing it as a bug. I had already filed a bug report myself.
July 17th, 2007 at Jul 17, 07 | 11:37 pm
>> I agree that this PDF is probably a “bad” PDF, but the reality is…
I agree with your point. PDF Kit does need to handle these cases – as you say, users have certain expectations that the stuff just works.
Earlier in the post and comments though there was some confusion as to whether the spaces were being ignored by Preview due to a bug (and why does it work for other PDF’s) and I wanted to make it clear to anyone reading that not all PDF’s are created equal (so to speak). Some PDF’s create more challenges than others (this would be one of the more challenging ones).
Sadly too, there isn’t anything really in the PDF spec that would suggest these problems and how to accommodate them. The reality is, someone has to physically come across one of the PDF’s in the wild and write up a bug.
You can imagine an obvious fix for this PDF would be to *always* insert a space after a comma (if no space is found – does that break with number sequences? – special case that…). Sadly though, another PDF appears one day with different problems that the “space after comma fix” doesn’t address. So you keep adding layers of rules….
I’ve certainly seen PDF’s so messed up that neither Preview now Reader come even close.
>> Thanks for filing it as a bug. I had already filed a bug report myself.
I should have waited … your bug just showed up (with a portion of the aforementioned PDF).
July 18th, 2007 at Jul 18, 07 | 10:19 am
My thinking is that, if there are no space chars in the PDF itself, then the algorithm must take into account the space between words and render it as space characters when selecting/copying text. There is clearly a space here in this particular PDF after the commas and semi-colons. There is no ambiguity about this, even for a “dumb” algorithm that doesn’t understand English.
So I wouldn’t say that the rule would be to always insert a space after commas and semi-colons (there are clearly cases where this shouldn’t happen, such as the use of the comma as a decimal separator in French and other languages), but rather that the rule needs to be able to “see” the space between words and to render that space as a space char. If I can see it (and if an OCR program can see it when scanning the text), then I expect Preview to be able to see it too.
My other point is that “bad” PDFs are only as bad as the programs used to create them (and the ways that these programs are used) are bad. In this case, the program used was Adobe Distiller 6 for Mac. Not exactly a rare/exotic PDF authoring tool… I expect Preview to be able to handle PDFs created by Adobe Distiller 6 for Mac, and I don’t think it’s an unreasonable expectation.
It would still be interesting to determine exactly what caused this particular PDF to be as “bad” as it is, but unfortunately, that’s probably beyond my capabilities.
July 18th, 2007 at Jul 18, 07 | 12:45 pm
While Distiller may be a common tool, I can imagine that it’s not the best. And that, because of the way it works – converting files from PostScript -, it may just not have the best/full information at hand for the job.
With ‘good’ PDF files in mind, Distiller (or at least an old Distiller?) may just not be the best solution for the problem. Systems that create PDF files directly may be preferable.
For example the simple files PDF files I just tested (created with Text Edit and the Print dialogue and pdfTeX respectively did reasonably well in terms of copy and paste).
July 18th, 2007 at Jul 18, 07 | 2:00 pm
I cannot test Acrobat Distiller 6, but, in my experience, Acrobat Pro CS3 (version 8) produces PDFs that are similar to the ones produced by Mac OS X itself or by the Export command in InDesign CS3. It may be that there have been improvements since Distiller 6, but it could also be that many factors other than the actual software version are involved. Maybe it also has to do with the original application that sent the file to Distiller (Quark Xpress?), with the font choices, with the specific formatting options used for this particular document, etc.
Not every designer uses the latest version of everything, and not every designer (in my experience) does things in the “normal” / expected way. There are just too many possibilities here. We simply need PDF viewers/readers that are able to handle most PDF files properly, just like we need web browsers that are able to handle most web pages properly, regardless of how badly coded they are.
July 18th, 2007 at Jul 18, 07 | 5:44 pm
>> the rule needs to be able to “see” the space between words and to render
>> that space as a space char. If I can see it (and if an OCR program can see it
>> when scanning the text), then I expect Preview to be able to see it too.
PDF Kit does have an algorithm that tries to determine where spaces are to be inserted. I’m sure OCR software is much more complex but what PDF Kit does is to look at the gaps between characters and determine if they are wide enough to warrant inserting a space. “Wide enough” is a complicated thing. Using the font size helps (a larger gap would be required for larger fonts for example). The problem is that you can never get it always right. If you’re too aggressive you end up inserting spaces in the middle of words, if you’re not aggressive enough, you run words together. You can pay with ratios all day and never get a magic number that works for all PDF’s.
To that end, for PDF Kit it was decided to go down this path as a last resort. In the example PDF we are talking about, there are spaces elsewhere in the PDF. In fact, but for the commas, the PDF is otherwise well-behaved. For this reason, PDF Kit is not aggressive with it. This is again, why I call it the worst kind of PDF — it half tries to do the right thing.
The other point is of course that you are a lot better than a computer will perhaps ever be at deciding where spaces should be by looking at a document. OCR software too would go the extra mile to use dictionary look-ups to decided the borderline cases.
I wish I could post images here. I could show you some interesting examples. I can show you this PDF with the each character bounded (and you can see that there is a missing space). It would be interesting too to post a PDF with only character bounds (no text) and see if you can decide where the space should be.
Again though, back to Preview, if Adobe is doing it, PDF Kit can as well — but it’s going to take considerable resources.
>> My other point is that “bad” PDFs are only as bad as the programs used to
>> create them (and the ways that these programs are used) are bad. In this
>> case, the program used was Adobe Distiller 6 for Mac.
Distiller 6 is only half the problem (or solution perhaps). It can be boiled down to garbage in, garbage out.
Distiller 6 (and other PDF creation tools) present a PDF “context” for the client application to render into. Anything rendered into the context will be dutifully recorded in a PDF rendering stream.
The problem is when the client application doesn’t render the spaces into the context. No spaces in, no spaces out.
As an example, take a PostScript file. These very typically are devoid of spaces (and why would you bother wasting bandwidth sending a space character to a printer that will ignore it anyway). Run the PostScript file into Distiller 6 and see what comes out.
Don’t misunderstand my intent here – I’m not trying to be either defensive of Preview or critical of your comments. PDF’s are not a well understood format and so I’m trying to expose some of the challenges that they present and the causes of these challenges. (Okay, perhaps that is being a bit defensive of Preview.)
July 18th, 2007 at Jul 18, 07 | 6:18 pm
John, if you can host your pictures somewhere, you can always insert HTML tags referring to them in your comments.
As for the rest, of course these are all valid points you make. I am sure it is more complex than it looks like. It always is :-). And I truly appreciate your insights.
Ultimately, though, I am still hoping that, some day, somehow, our computers will become really good at what they are supposed to be good at, i.e. automate repetitive tasks where no human intervention should be required. As a professional Mac user, I cannot help but feel that the potential of computers in general (and of the Mac in particular) as professional tools is not fully tapped, for a variety of reasons (focus on “consumer-level” products, lack of resources, lack of real competition in the market, etc.). It is a frustrating and it is a frustration that, as a professional Mac user, I experience on a daily basis with a myriad of “smaller” issues such as the one that started this thread.
July 18th, 2007 at Jul 18, 07 | 9:07 pm
Part of the issue is that PDF is such a broad category of files, that it’s challenging to make broad assertions about how PDF files should be handled. I expect that if a designer handed you an Adobe Illustrator .AI file that had been autogenerated from some other application, it would make sense to you that the text was oddly represented… but in a Distiller PDF, that’s pretty much what you’re being given. Likewise, if I gave you a JPEG, you would understand that you couldn’t copy and paste text out of it; and some PDFs are nothing more than JPEGs with page numbers. On the other hand, a well-made PDF that came from software with native support can give you perfect copy/pastable text as well as all sorts of other features.
Distiller is common, but it’s a hack. It takes PostScript data, usually from an application that thinks it’s sending data to a printer, and wraps it up in a PDF. This gives you cross-platform viewing and page numbers, but it can’t magic spaces into the text where there were none before; and Preview and Acrobat Reader alike are left guessing.
This is a case of poor tools (Distiller) giving you poor results (a badly formed PDF).
And actually I think your Web browser analogy is fairly apt — a poorly made Web site will often look good at first glance in all the browsers, but try to do something slightly less common — change text size, say — and you’ll find that the behavior across browsers suddenly deviates wildly. Likewise, a Distiller PDF gives you the core behavior — a file you can view and print cross platform — but go beyond the simplest interaction and you’re left dealing with software having to guess about the intent of some other piece of software, without having enough information to work from.
July 19th, 2007 at Jul 19, 07 | 10:43 am
Dan: My point was that, whatever the PDF file format was initially designed for and regardless of how it is generated, it is now commonly used as a file format for sharing print-ready documents, and in many cases the sharing is not intended to preclude the recipient from using the document in a variety of ways, including selecting chunks of text to copy and reuse them elsewhere.
Today’s PDF viewing tools need to adapt not just to the evolution of the file format itself, but also to the evolution of its uses. If people perceive PDF as a suitable file format for sharing text files, then PDF viewers must also suit this purpose, whatever the technical challenges are. The actual, real-world uses of a technology are just as important as—if not more than—its originally intended uses.
July 19th, 2007 at Jul 19, 07 | 1:24 pm
I like your ideals, I just don’t think that can happen in the real world, that’s all :-)
The PDF spec can do everything you want, and PDFs generated with good tools can too. Over time, I reckon the average quality of PDFs will go up as people use better tools.
July 19th, 2007 at Jul 19, 07 | 1:31 pm
There’s a lovely Mac program called DevonThink Pro Office which I use for document management; the Pro Office version includes an OCR engine that works for PDFs. Since John discovered the document in question, I went ahead and downloaded it and ran it through DT Pro Office’s OCR engine. For what it’s worth, it seems to have handled things perfectly.
Without OCR, it behaved like Preview (I assume it uses PDFKit); after OCR, it handled text selection correctly (and, since it saves the PDF with the OCR data, so did Preview). If you run into this type of problem frequently, or have other reasons to run OCR on PDFs or scans, you might look at DevonThink.
July 19th, 2007 at Jul 19, 07 | 2:02 pm
Thanks for the suggestion. Interestingly, DEVONtechnologies’ own freeware PDF2RTF service suffers from the same problem as Preview, i.e. it fails to “see” the spaces after the commas and semi-colons and the resulting RTF file fails to include the required space characters in those locations. Presumably PDF2RTF is based on the same underlying engine as Preview, whereas the DEVONthink Pro Office has its own algorithms. Of course, I already own Acrobat Pro 8 (CS3), so there’s no real incentive for me to spend money on another product for this particular purpose—although of course DEVONthink Pro Office has several other intriguing features.
July 19th, 2007 at Jul 19, 07 | 3:33 pm
DT Pro Office is actually running OCR; not just converting the text data from the PDF. Conceptually, it almost seems like a step backward — basically throwing away the text data and treating the PDF like an image — but if the text data in the PDF is junk, you’ll get better results from OCR.
I don’t know how PDF2RTF is implemented, but I assume since it’s free (and decent OCR engines are expensive); and since it’s fairly small (and OCR engines are big) that it’s probably extracting the text with either PDFKit or something similar, and would therefore have similar limitations to Preview, as you saw.